 |
Rainbow Notes: Technical stuff
|
 |
The principle behind it is simple: the applet functions as an electronic
sheet of music and can, when requested, convert this symbolic information
into an array of byte values that will sound like the corresponding music
when sent to the loudspeaker of your machine through your WWW browser.
(See the
sun.audio.* class package info for details.) Performing the actual
byte-by-byte conversion is the tricky part, but that's nothing the
end-level users will need to concern themselves with. Those who are
interested can take a look at the rough description of it further down
on this page.
For each melody, only the symbolic note data needs to be loaded from
the server. That's a very compact way of representing sound. So
compact, in fact, that I decided to write a Java class, named
"Melody",
for making use of these data files in general applets.
|
Why a Melody class?
|
|
The main advantage is storage space (consequently download time) and to some
extent sound quality.
A half-minute tune, taking up more than 230 kilobytes as a normal audio
file (or 115 K at 2:1 compression) normally doesn't take more than
about 2 K as note data. That's a significant gain if you've got a slow
connection or a crowded network. However, to process the notes into audible
data once they're in your computer takes a bit of time too (though not as
much time as the "making" in Ranibow Notes, where I haven't optimized
the algorithm), so the gain won't
be quite that dramatic, but even for a run-of-the-mill machine it should
beat downloading a normal audio file through a 28.8 modem hands down.
What about the sound quality? Well, since this audio information hasn't
been recorded through a physical microphone, it doesn't have any static
or any other real-world distortion. It sounds clearer, but then again
the things you can create with the melody editor are rather limited and
primitive. They might not live up to the coolness you'd want for your
own applet sounds. So go write your own melody editor! It's not that
difficult.
Oh yeah, and people who -- like myself -- know very little about music and
can't handle any instrument may for that reason alone find Rainbow Notes an
occasionally useful tool for creating applet melodies.
|
Functions of the Melody class
|
|
Melody just loads the note data and converts it into an audio byte
array. You
can then play that by sending it as an AudioDataStream to the AudioPlayer.
Each melody object has an InputStream variable called soundStream, which
is preferably used for that purpose.
mel.soundStream=new AudioDataStream(new AudioData(mel.rawAudio));
AudioPlayer.player.start(mel.soundStream);
If you'd rather "loop" the melody, create a ContinuousAudioDataStream instead:
mel.soundStream=new ContinuousAudioDataStream(new AudioData(mel.rawAudio));
AudioPlayer.player.start(mel.soundStream);
You can stop it by calling the AudioPlayer.player.stop() method:
AudioPlayer.player.stop(mel.soundStream);
|
Building sound from scratch
|
|
An AudioDataStream (or ContinuousAudioDataStream) object is based on an
array of byte values (0-255) representing sound amplitudes in the range
-8192 to 8191. The applet first computes the latter value by adding
together sound contributions from all voices (which in turn are products
of waveform and envelope values), and then picks the final
byte value from a lookup table prepared during initialization. This
has to be done 8000 times for each second of resulting music, which is
why it takes a while before you get to hear anything.
If we have two voices, red and blue, defined by the waveform and
envelope curves
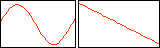 and and 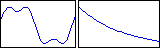
and a bar with these notes

the note data is converted into an amplitude curve like this:
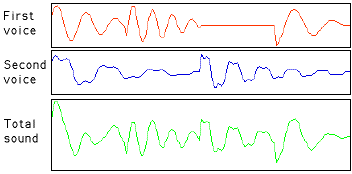
(In reality the curve oscillates much more quickly, but this is just a
schematic illustration.)
Now, this data in turn needs to be converted to
a form the AudioPlayer Java class can understand.
Assuming I've got the rules behind the byte value conversion right,
this is how it's intended to work:
| In range | Out range | In range | Out range |
|---|
| 0-31 | 255-240 | -32--1 | 112-127 |
| 32-95 | 239-224 | -96--33 | 96-111 |
| 96-223 | 223-208 | -224--97 | 80-95 |
| 224-479 | 207-192 | -480--225 | 64-79 |
| 480-991 | 191-176 | -992--481 | 48-63 |
| 992-2015 | 175-160 | -2016--993 | 32-47 |
| 2016-4063 | 159-144 | -4064--2017 | 16-31 |
| 4064-8191 | 143-128 | -8192--4065 | 0-15 |
The maximum volume I've given any voice is 4032. This creates a problem:
what happens if three or more voice sound data contributions add up
to more than 8191 (or less than -8192)? I avoid this by first searching
through the note data for such occurrences, find the theoretical maximum
volume and use that to compute a scale factor I later use throughout
the making of the melody. The inevitable result is that if you use many
voices at the same time, they will have to "share" the max volume
and each one will sound slightly weaker than if they had been played
individually.
|









